Transformer ( Part 3: Transformer Architecture )
Encoder & Decoder
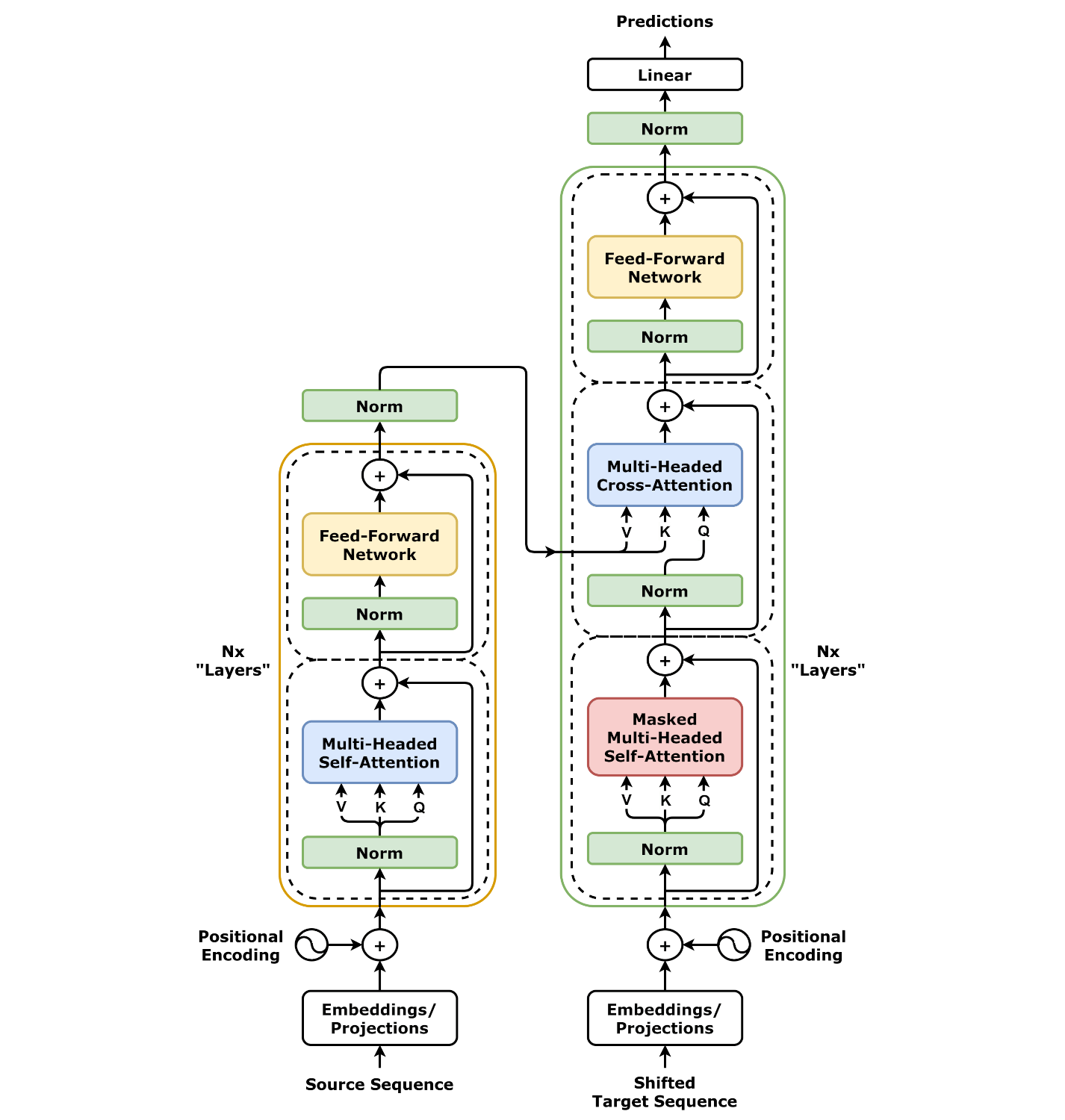
The Transformer consists of two main parts: an encoder and a decoder. They are connected by Cross-Attention.
- Encoder: Processes the input sequence using multiple layers of self-attention and feed-forward networks.
- Decoder: Takes the encoder’s output and generates the target sequence using self-attention and cross-attention mechanisms.
The Transformer Architecture:
Token Embedding
- Converts input tokens into dense vector representations.
- Typically implemented using word embeddings.
- Works alongside positional encoding to maintain sequence order.
Positional Encoding
Since Transformers do not process sequences sequentially like RNNs, positional encodings add order information to embeddings.
The formula for positional encoding is:
$$
PE_{(pos, 2i)} = \sin(pos / 10000^{2i/d})
$$
$$
PE_{(pos, 2i+1)} = \cos(pos / 10000^{2i/d})
$$
where $pos$ is the position in the sequence, $i$ is the dimension index, and $d$ is the embedding size.
Self-Attention Mechanism
The core of the Transformer is the self-attention mechanism, which computes relationships between tokens within a sequence.
The input embeddings are transformed into Query (Q), Key (K), and Value (V) matrices:
$$
Q = XW^Q, \quad K = XW^K, \quad V = XW^V
$$The attention scores are computed using the scaled dot-product attention:
$$
\text{Attention}(Q, K, V) = \text{softmax} \left(\frac{QK^T}{\sqrt{d_k}}\right) V
$$where $\sqrt{d_k}$ is a scaling factor to prevent large gradients.
The result is a weighted sum of the values $V$.
Multi-Head Attention
Instead of a single attention function, Transformers use multi-head attention, which allows the model to learn multiple attention patterns.
$$
\text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, …, \text{head}_h) W^O
$$
Each attention head captures different aspects of relationships in the sequence.
Feed-Forward Network (FFN)
Each Transformer layer contains a feed-forward network:
$$
FFN(x) = \max(0, xW_1 + b_1) W_2 + b_2
$$
This introduces non-linearity and improves representation power.
Residual Connections & Layer Normalization
Residual connections help prevent vanishing gradients:
$$
\text{Layer Output} = \text{LayerNorm}(x + \text{SubLayer}(x))
$$Layer Normalization stabilizes training and ensures consistent distribution across different batches.
Cross-Attention in Decoder
The decoder has an additional attention layer:
- The Query comes from the decoder.
- The Key and Value come from the encoder output.
- This enables the decoder to focus on relevant encoded information.
Masking Mechanisms
- Padding Mask: Prevents attention from being applied to padding tokens. (Encoder)
- Look-Ahead Mask: Ensures that the decoder only attends to previous tokens, maintaining auto-regressive generation. (Decoder)
GPT’s Decoder-Only Architecture
Unlike the standard Transformer model, GPT removes the encoder and relies solely on stacked decoder layers. This makes it an autoregressive model, meaning it generates text token by token, predicting each next token based on previous ones. This decoder-only Transformer is designed for autoregressive text generation, making it highly effective for applications like chatbots, code generation, and creative writing.
Transformer ( Part 3: Transformer Architecture )
https://kongchenglc.github.io/blog/2025/03/11/Transformer-3/