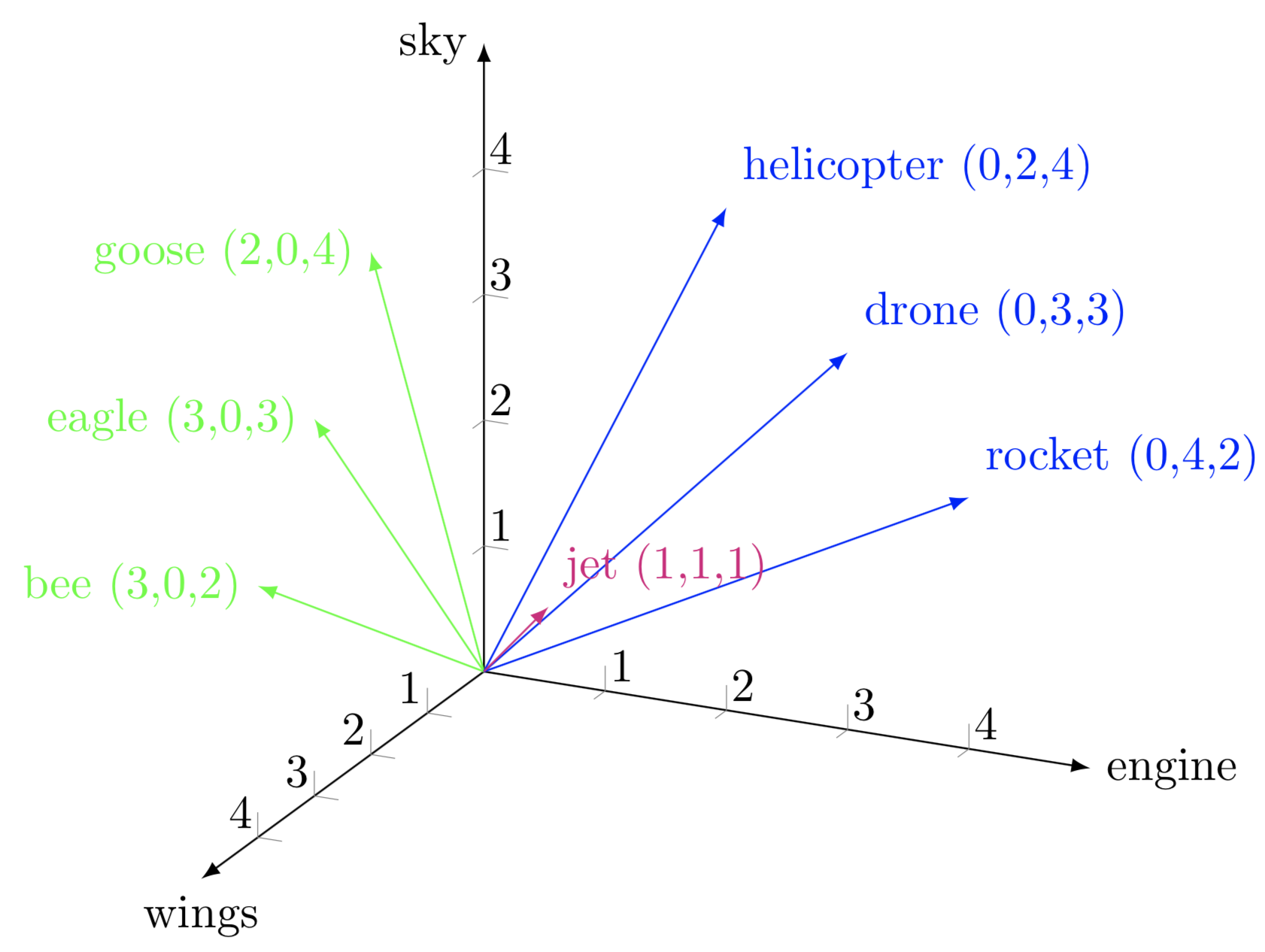
Word Embedding is one of the most fundamental techniques in Natural Language Processing (NLP). It represents words as continuous vectors in a high-dimensional space, capturing semantic relationships between them.
Why Do We Need Word Embeddings?
Before word embeddings, one common method to represent words was One-Hot Encoding. In this approach, each word is represented as a high-dimensional sparse vector.
For example, if our vocabulary has 10,000 words, we encode each word as:
$$
\text{dog} = [0, 1, 0, 0, \dots, 0]
$$
However, this method has significant drawbacks:
- High dimensionality – A large vocabulary results in enormous vectors.
- No semantic similarity – “dog” and “cat” are conceptually related, but their one-hot vectors are completely different.
Word embeddings solve these issues by learning low-dimensional, dense representations that encode semantic relationships between words.