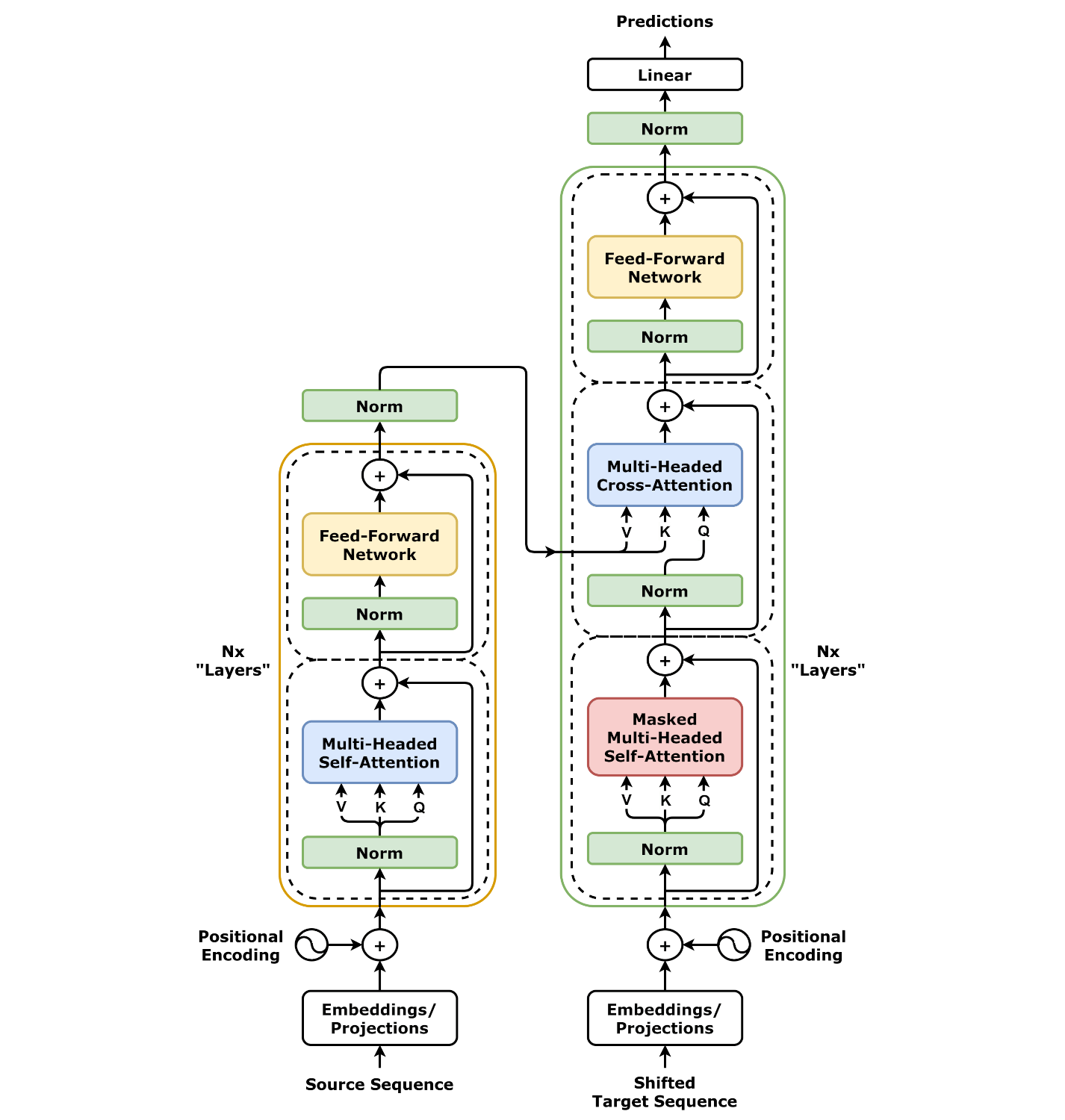
Fundamentals
HTML
SEO (Search Engine Optimization)
- Use semantic HTML elements (
<article>, <section>, <nav>, <header>, <h1><h2>etc.) - Set meaningful
<title>and<meta name="description" content="xxx">for each page. - Use of
<alt>Attributes on Images - Use
<meta name="robots">orrobots.txtto control indexing.
Render Process
DOM + CSSOM => Render Tree
Layout(Size, Position) => Paint(Color, Background) => Composite
Recalculate Style => Reflow => Repaint => Compositing